While working on GlobalProtect on one of my Palo Alto firewalls, I ran into a strange behavior, and I don’t see any documentation about it on the internet, so I figured I should write something about it here.
At my company, we are starting to deploy GlobalProtect for remote-access user VPN, and on the firewalls at a couple of locations, we were authenticating users with locally-created user accounts on the firewalls. This of course is a bad idea and is completely non-scalable. At the same time, though, we are starting to deploy a new corporate Active Directory, and we already have all our users in Office 365, so I started working on VPN authentication using AD and Azure MFA. This was a whole other challenge. Suffice it to say, I settled on using Microsoft NPS as a RADIUS server, and using the NPS Extension for Azure MFA to trigger an MFA prompt. This works pretty well, a RADIUS request hits NPS, which authenticates against local AD first. If the authentication succeeds, it sends a request up to Azure AD, matching the UPN of the local AD user with Azure AD, and triggering a MFA request using whatever MFA method the user has set as default in O365. This even works for SMS codes or phone calls.
So I had a workable RADIUS authentication method that provided MFA using Azure MFA. I still needed to support the local authentication method as well in GlobalProtect though. I created an Authentication Sequence for it, using the local auth profile first, then the RADIUS auth profile second, and I assigned this authentication sequence on the GP Portal and Gateway. And here is where the weirdness started.
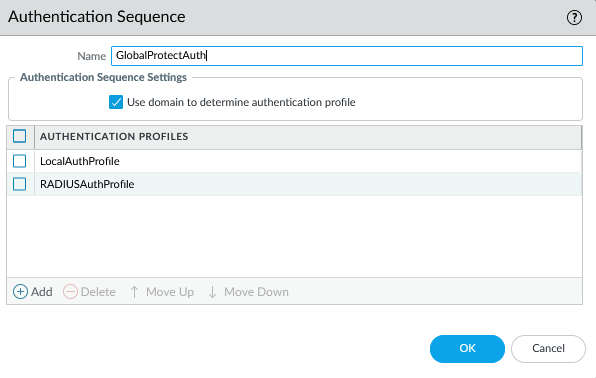
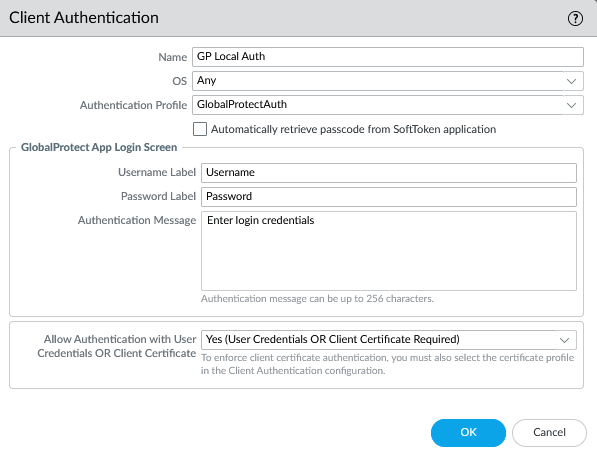
When a user with a local account would connect, it would work normally. They’d enter their username and password, and within a couple seconds they’d be connected. However when a user would log in with a RADIUS username and password, they’d get an Azure MFA prompt like normal, then the login process would sit there for about 90 seconds, then eventually it would prompt them to log in again. They’d enter their username and password again, they’d get another MFA prompt, and finally they’d be connected to the VPN. This was clearly not a satisfactory experience, so I started trying to figure out why.
If you’re familiar with configuring GlobalProtect, you know that there are two separate components to it, the Portal and the Gateway. The Portal is the initial point of contact, where a user authenticates. The Portal then tells the client what Gateway to connect to (or offers multiple choices). The client then connects to a Gateway and this is what the client actually builds a VPN connection to. In many cases the Portal and Gateway exist on the same firewall device, but they don’t necessarily have to. The key to this annoying multiple-authentication behavior is that the client has to authenticate to both the Portal AND the Gateway independently. To reduce the annoyance of having to authenticate twice, both the Portal and the Gateway have the ability to generate and/or accept an Authentication Bypass Cookie. This is a cookie that the client receives that can be used in lieu of an actual authentication challenge. Generally you configure the Portal to generate a cookie, and the Gateway to accept it. Then when the client authenticates successfully to the Portal, it gives the cookie to the Gateway and is allowed to connect, rather than having to authenticate again.
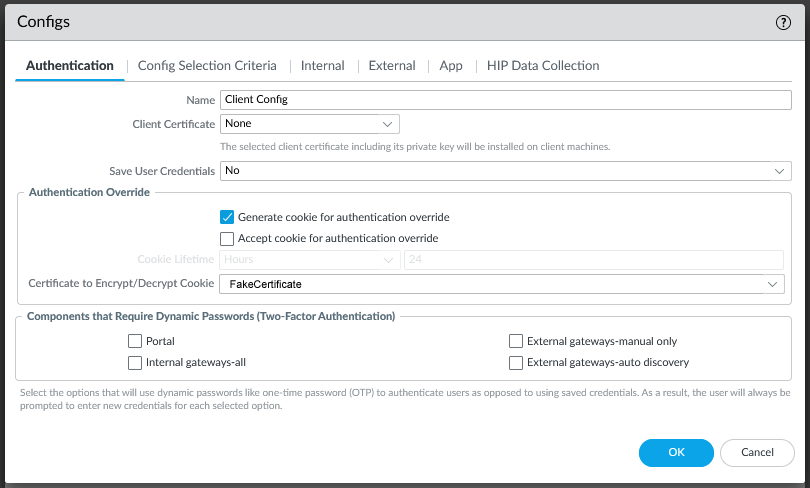
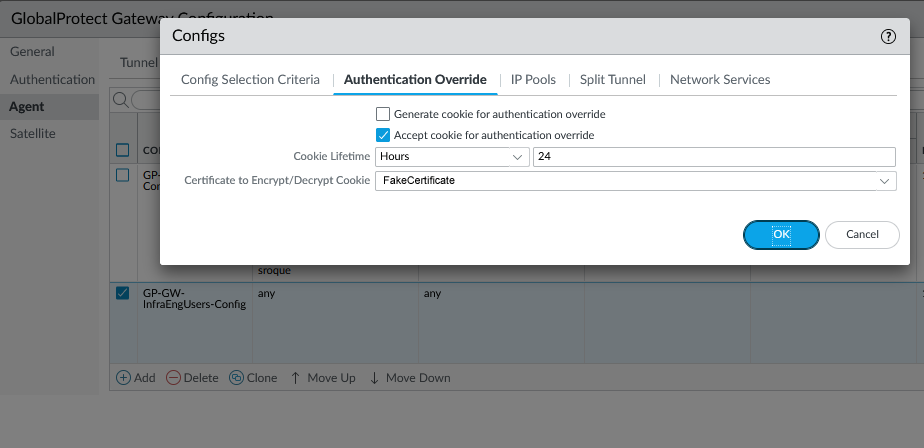
This is how my firewall was configured, but for some reason it was not working. The user would authenticate to the Portal, but then they’d have to wait for 90 seconds, then they’d be prompted to authenticate to the Gateway. For some reason, the authentication bypass cookie wasn’t being accepted by the Gateway.
I fought with this issue for a while, and eventually opened a support case with Palo Alto. This was an extremely unsatisfying experience, that eventually ended with the support person telling me that the cookie doesn’t actually pass through the username and password, and the behavior I was experiencing was just how it works.
This was, of course, absolute nonsense.
After a lot more parsing of mp-log authd.log, I finally got a complete picture of what was happening. The issue was that I was using an authentication sequence for the Gateway, with a local auth profile first in the sequence. When the authentication passed on the Portal, it moved on to the Gateway. The Gateway saw that there were multiple authentication profiles that the auth could match, so it ignored the cookie and attempted to authenticate against the profiles in turn. The local auth profile returned a reject immediately, so it moved on to the RADIUS auth profile. This all happened very quickly after the initial RADIUS auth succeeded, so NPS treated the second authentication as just a retransmit of the initial request and ignored it. The firewall didn’t know this though, so it waited for the RADIUS timeout set in the RADIUS authentication profile. This value was set for a long time, 90 seconds, to give users enough time to deal with the MFA prompt from Azure. So the user would just sit there waiting for RADIUS to time out, then eventually when it did, they got prompted to authenticate again. They’d put in their username and password again, respond to the MFA challenge, and would finally be logged in to VPN.
The solution to this issue ended up being really simple. The authentication only actually needs to happen on the Portal, and all the Gateway should need to do is to decrypt the authentication bypass cookie. So there is no reason why the Gateway needed the full authentication sequence. I changed the authentication method to just the local authentication profile, and suddenly my problems went away. A user would authenticate to the Portal, would receive a cookie, and would be passed through the Gateway.
Thanks for nothing, Palo Alto support.
Currently drinking: Sam Adams Octoberfest